Copy Semantics
Value. To learn how value classes affect copy operations,
Examples
Grow a Classification Tree
Grow a classification tree using the ionosphere data set.
load ionosphere tc = fitctree(X,Y)
tc =
ClassificationTree
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: {'b' 'g'}
ScoreTransform: 'none'
NumObservations: 351
Properties, Methods
Control Tree Depth
You can control the depth of the trees using the MaxNumSplits, MinLeafSize, or MinParentSize name-value pair parameters. fitctree grows deep decision trees by default. You can grow shallower trees to reduce model complexity or computation time.
Load the ionosphere data set.
load ionosphere
The default values of the tree depth controllers for growing classification trees are:
-
n - 1forMaxNumSplits.nis the training sample size. -
1forMinLeafSize. -
10forMinParentSize.
These default values tend to grow deep trees for large training sample sizes.
Train a classification tree using the default values for tree depth control. Cross-validate the model by using 10-fold cross-validation.
rng(1); % For reproducibility MdlDefault = fitctree(X,Y,'CrossVal','on');
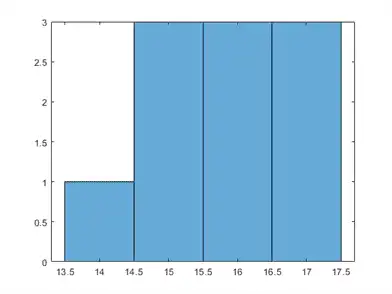
Draw a histogram of the number of imposed splits on the trees. Also, view one of the trees.
numBranches = @(x)sum(x.IsBranch); mdlDefaultNumSplits = cellfun(numBranches, MdlDefault.Trained); figure; histogram(mdlDefaultNumSplits)
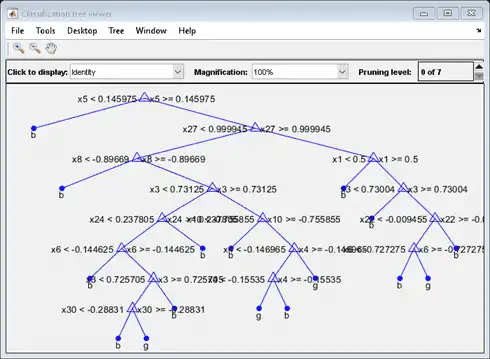
view(MdlDefault.Trained{1},'Mode','graph')
The average number of splits is around 15.
Suppose that you want a classification tree that is not as complex (deep) as the ones trained using the default number of splits. Train another classification tree, but set the maximum number of splits at 7, which is about half the mean number of splits from the default classification tree. Cross-validate the model by using 10-fold cross-validation.
Mdl7 = fitctree(X,Y,'MaxNumSplits',7,'CrossVal','on');
view(Mdl7.Trained{1},'Mode','graph')
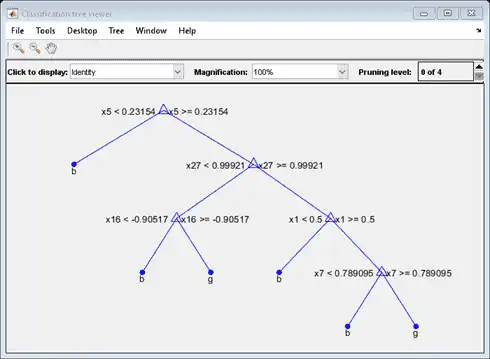
Compare the cross-validation classification errors of the models.
classErrorDefault = kfoldLoss(MdlDefault)
classErrorDefault = 0.1168
classError7 = kfoldLoss(Mdl7)
classError7 = 0.1311
Mdl7 is much less complex and performs only slightly worse than MdlDefault.