k-Nearest Neighbor Search and Radius Search
Given a set X of n points and a distance function, k-nearest neighbor (kNN) search lets you find the k closest points in X to a query point or set of points Y. The kNN search technique and kNN-based algorithms are widely used as benchmark learning rules. The relative simplicity of the kNN search technique makes it easy to compare the results from other classification techniques to kNN results. The technique has been used in various areas such as:
-
bioinformatics
-
image processing and data compression
-
document retrieval
-
computer vision
-
multimedia database
-
marketing data analysis
You can use kNN search for other machine learning algorithms, such as:
-
kNN classification
-
local weighted regression
-
missing data imputation and interpolation
-
density estimation
You can also use kNN search with many distance-based learning functions, such as K-means clustering.
In contrast, for a positive real value r, rangesearch finds all points in X that are within a distance r of each point in Y. This fixed-radius search is closely related to kNN search, as it supports the same distance metrics and search classes, and uses the same search algorithms.
k-Nearest Neighbor Search Using Exhaustive Search
When your input data meets any of the following criteria, knnsearch uses the exhaustive search method by default to find the k-nearest neighbors:
-
The number of columns of
Xis more than 10. -
Xis sparse. -
The distance metric is either:
-
'seuclidean' -
'mahalanobis' -
'cosine' -
'correlation' -
'spearman' -
'hamming' -
'jaccard' -
A custom distance function
-
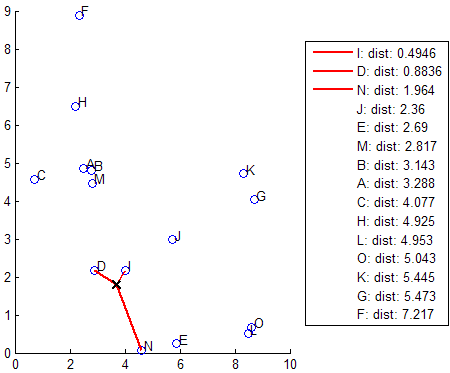
knnsearch also uses the exhaustive search method if your search object is an ExhaustiveSearcher model object. The exhaustive search method finds the distance from each query point to every point in X, ranks them in ascending order, and returns the k points with the smallest distances. For example, this diagram shows the k = 3 nearest neighbors.
k-Nearest Neighbor Search Using a Kd-Tree
When your input data meets all of the following criteria, knnsearch creates a Kd-tree by default to find the k-nearest neighbors:
-
The number of columns of
Xis less than 10. -
Xis not sparse. -
The distance metric is either:
-
'euclidean'(default) -
'cityblock' -
'minkowski' -
'chebychev'
-
knnsearch also uses a Kd-tree if your search object is a KDTreeSearcher model object.
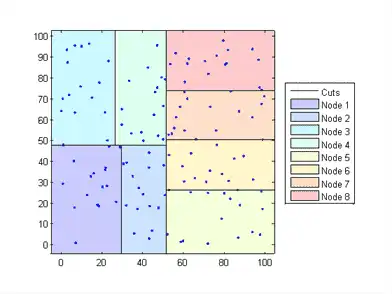
Kd-trees divide your data into nodes with at most BucketSize (default is 50) points per node, based on coordinates (as opposed to categories). The following diagrams illustrate this concept using patch objects to color code the different “buckets.”
When you want to find the k-nearest neighbors to a given query point, knnsearch does the following:
-
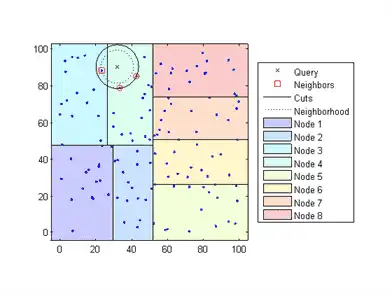
Determines the node to which the query point belongs. In the following example, the query point (32,90) belongs to Node 4.
-
Finds the closest k points within that node and its distance to the query point. In the following example, the points in red circles are equidistant from the query point, and are the closest points to the query point within Node 4.
-
Chooses all other nodes having any area that is within the same distance, in any direction, from the query point to the kth closest point. In this example, only Node 3 overlaps the solid black circle centered at the query point with radius equal to the distance to the closest points within Node 4.
-
Searches nodes within that range for any points closer to the query point. In the following example, the point in a red square is slightly closer to the query point than those within Node 4.
Using a Kd-tree for large data sets with fewer than 10 dimensions (columns) can be much more efficient than using the exhaustive search method, as knnsearch needs to calculate only a subset of the distances. To maximize the efficiency of Kd-trees, use a KDTreeSearcher model.
What Are Search Model Objects?
Basically, model objects are a convenient way of storing information. Related models have the same properties with values and types relevant to a specified search method. In addition to storing information within models, you can perform certain actions on models.
You can efficiently perform a k-nearest neighbors search on your search model using knnsearch. Or, you can search for all neighbors within a specified radius using your search model and rangesearch. In addition, there are a generic knnsearch and rangesearch functions that search without creating or using a model.
To determine which type of model and search method is best for your data, consider the following:
-
Does your data have many columns, say more than 10? The
ExhaustiveSearchermodel may perform better. -
Is your data sparse? Use the
ExhaustiveSearchermodel. -
Do you want to use one of these distance metrics to find the nearest neighbors? Use the
ExhaustiveSearchermodel.-
'seuclidean' -
'mahalanobis' -
'cosine' -
'correlation' -
'spearman' -
'hamming' -
'jaccard' -
A custom distance function
-
-
Is your data set huge (but with fewer than 10 columns)? Use the
KDTreeSearchermodel. -
Are you searching for the nearest neighbors for a large number of query points? Use the
KDTreeSearchermodel.